



Making AI cheaper, smaller, and faster
Building smaller systems, one weight at a time

“When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all.” — Building effective agents, published by Anthropic
There’s this old urban legend about the American space pen. Stop me if you have heard about it, but this is how it goes: NASA astronauts needed a pen to take notes in space, but the classic ballpen design fails in zero gravity. So, they spent years of research and millions of dollars in funding to find a solution. Meanwhile, the Russians used pencils.
It’s probably not true; it’s an urban legend after all. However, the story sheds an alarming light on our tendency to use excessive force on trivial problems. Shooting birds with cannons. Cracking nuts with sledgehammers. Burning down houses to kill spiders. The instinct is so strong that we even have an abundance of expressions for the same phenomenon.
Our toasters are connected to the internet. We order online from the store within walking distance. We travel alone in gigantic seven-seated SUVs.
This tendency is also painfully apparent in our newfound large language model usage. A GPT prompt is much more powerful than a Google search, so our brains are already defaulting to it. The internet saved us from having to store massive tomes of encyclopedias on our bookshelves, Google saved us from browsing the tables of contents, and ChatGPT saved us from knowing what we are looking for.
In 2025, we are prompting instead of thinking.
We can quantify the trends by looking at the evolution of AI spend. For instance, the mean spend per company by quarter, as reported by Ramp1, shows a 2x-3x increase for industries like financial services or healthcare & biotech.

On the other hand, look at one of my favorite graphs, visualizing the cost of full human genome sequencing since its inception. Note the log scale: one bar on the y-axis equals a tenfold increase.

The message is staggering. What used to be a $100,000,000 investment (per genome!) is now a mere $1000 commodity, affordable to a wide range of consumers.
We cannot fight technology, nor should we; however, we can make it more accessible. Despite the culturally dominant romantic and idealistic view of entrepreneurship as pushing the boundaries of what’s possible, the true glory is bringing what’s possible closer to what’s routine.
So, there’s an enormous need to optimize AI costs. That’s a no-brainer. When there’s a need, there’s a supply, but there’s also a hype. Is “cheap AI” just another “.com” or “proprietary tech” of the startup zeitgeist?
In our inaugural post, we’ll show you the established and emerging ideas to make AI feasible. In the next couple of sections, we'll review
the problem,
the solutions,
and the startups that attempt to solve the problems.
Let's start with the problem.
More weights, more problems
No matter how oversized the packaging is, the heart of every AI system is a neural network. For example, let's consider a large language model, or an LLM in short. Since ChatGPT exploded into our lives in 2022, startups and enterprises adopted them faster than you can say “dotcom”, so it's time to pop the hood.
From a high level, you can imagine an LLM as a black box, transforming data into prediction. You feed it with a prompt, and ye shall receive a response. We'll open these black boxes to show if there's room to improve. Don't worry; I'll be gentle.

To understand the black box model, consider another one: a car. You rotate the steering wheel, and the car moves. You slam the accelerator, and the car launches forward. An input is given, an output is received.
Just like in cars, there's a finely engineered mechanism that turns your input into the output. The accelerator is connected to a throttle, which opens up to widen the flow, allowing more gas-air mixture into the engine. Thus, the pistons fire faster, resulting in more speed.
For LLMs, we have tokenizers, embeddings, attention blocks, feed-forward layers, and several others instead of throttles and pistons. This is called the architecture. Currently, the transformer architecture is dominating the machine learning world.

If you are more technical, here’s how the transformer architecture works. First, the tokenizer converts your prompt into a sequence of high-dimensional vectors. Roughly speaking, each word corresponds to a token, which is turned into a single vector. This sequence of vectors are passed through the embedding layer, converting the individual vectors into lower-dimensional ones that reflect their underlying semantic meaning. Then, the vectors are passed through a series of attention blocks and feedforward layers. Each attention block updates the vector representations to include context-specific information. For instance, the word “bear” bears different meanings in the sentences “bear with me” or “the bear is about to attack.” Finally, the feedforward layers take our transformed vectors and predict what should be next. The prediction is then turned back into a token, and the process starts again.
If you want more detail, check out this magnificient video below by 3Blue1Brown.
One more level of resolution, then we can stop. Just like a cog keeps a mechanical part running, a component of a LLM is run by billions of elementary mathematical operations, like addition or multiplication. These are governed by billions of parameters (called weights) that are tuned during the training process. In the words of 3Blue1Brown, you can imagine each of them as dials that you can turn.

It’s quite astounding. I know, we are here to do (or at least find) business, but think about it. Pile up a bunch of mathematical operations and stir them until you can converse with the result.
Here comes the issue. The cost of running an LLM boils down to the number of parameters and the speed of these mathematical operations. Let's look at the trends to gauge the magnitude of the problem.
According to Our World in Data, this is how the parameter count of notable models — like ResNet or the GPT families — grew over time. Again, the y-axis is logarithmic, so one bar up equals a tenfold increase.

(There is no official data for GPT-4, so it is not visualized in this plot. However, it is estimated to have 1.76 trillion parameters, putting it above all the others in the chart.)
When you have trillions of floating point operations (FLOP-s), the price of inference can run up to a visible amount. Moreover, the individual operations require specialized hardware, often with massive energy consumption per device. That’s the bad news.
The good news is that each degree of granularity offers opportunities to cut costs and improve speed.
Let’s take a look at them one by one.
Pruning weights and costs
Previously, we have looked at neural networks on two levels:
the high-level architecture,
and the low-level mathematical operations.
Each one presents a variety of approaches to optimize the model's efficiency.
On the level of architecture, we can trim out layers or even rebuild the entire architecture by coming up with smaller models. On the level of fundamental mathematical operations, we can optimize the computations for the hardware or build specialized hardware.
In the following, we’ll overview each method's promises, limitations, and costs.
Make models smaller
The straightforward way to reduce the costs of running a model is to make a smaller one. This is entirely a software problem, so you can get started immediately with a laptop and a small reserve of cloud computing credits. Downside is, as the barrier of entry is low, the competition is fierce.
According to my research, there are four major methods, ranging from “sure, gimme a few hours” to “I'll need a research team and five years.” Almost all methods come at the cost of precision, so it's a matter of finding the right tradeoff. A 10x faster and cheaper model is often worth losing a couple of percent of accuracy.

The simplest method is quantization, which reduces the size of the inputs and the parameters. Let me elaborate. In neural networks, inputs and weights are usually represented by 64-bit double-precision floats. (That is, a sequence of 64 zeros and ones.) The more bits we use, the more accurate the computations are. Unfortunately, more bits also imply more memory and slower execution time.
By giving up the precision, we gain a faster and smaller model. This is achieved by approximating 64-bit doubles with 16-bit or even 8-bit integers. Think of this as a fancy way of rounding. Say, the parameter 0.48752287912 is rounded to 0.5, and the input 0.11765398272 is to 0.125. Try computing the products by hand and see which one is faster. (If you dare.)

Quantization is so common that it's already available in frameworks such as PyTorch, so a skilled builder can get started right away. You also don’t need to train a model from scratch, saving the precious compute time. The downside is that you need full access to the model weights, which is not possible for closed-source models, such as OpenAI’s GPT-4 or Anthropic’s Claude.
Similarly to quantization, another post-training method is weight pruning. There, instead of compressing the double precision floats, weights are randomly zeroed, resulting in sparse parameter matrices that are smaller to store and faster to use. It sounds quite extreme, but it can work surprisingly well. (One of the fundamental papers in the topic is the aptly titled Optimal Brain Damage, reflecting on the destructive nature of pruning.)

The biggest downside of the post-training methods, such as quantization and pruning, is that they require access to the entire model, not just its predictions through an API. If that's not an option, there's the method of knowledge distillation, that is, training a smaller model (called student) to approximate a larger one (called teacher). The main difficulty of distillation is having to design an architecture for the student and train it on a dataset obtained by running inference on the teacher model.

Distillation is a widely used method, and if you are a regular LLM prompter, you have almost certainly interacted with a distilled model, like GPT-4o-mini or Claude Haiku.
However, if you have the brains and the dollars, you can even design a new architecture and train it from scratch. This is a high-risk endeavor, but successfully pulling it off yields huge rewards. One recent example is DeepSeek, a model that took the world by storm. (Although they had other aces up their sleeves besides the improved transformer architecture.)
Training a so-called foundation model (such as GPT-4, Mistral Large, Claude Sonnet, or DeepSeek-V3) is resource-intensive, both in terms of computing and data. Thus, despite the advances, the barrier to entry remains high. Even the lauded DeepSeek-V3 cost $5.5 million to train. Granted, this is an order of magnitude better than the $100 million bill training GPT-4 left, but $5.5 million is still no pocket money. (At least, not for a broke Eastern European punk like me.)
All the tools we've seen so far work on the level of software. However, there are plenty of opportunities for hardware as well.
Let's see them!
Make operations faster
Previously, we looked at methods that make AI cheaper by reducing the number of operations. However, there's another way of looking at the problem: make said operations faster. The two main approaches to this are to optimize the code on the hardware level or build specialized hardware.
Let's talk about low-level optimization first. Sure, you most likely work with models inside Python (or any other language via API calls), but ultimately, that code is translated to lower and lower levels until you reach the processor executing the fundamental operations. This can be an Intel CPU, an ARM chip, an nVidia GPU, or any other processor.
However, the machine learning code you write in Python is not optimized for the hardware. To do that, you have to go a couple of layers deeper. For instance, the Tinygrad framework achieves speedup by writing custom GPU kernels and just-in-time compilation.
Look at Tinygrad’s self-reported stack, comparing the framework with the mainstream ones like PyTorch and TensorFlow. They claim to work directly with low-level code, avoiding the restrictions given by third-party tools like CUDA.

In our modern software engineering field, where the technical details are abstracted away and hidden even from the developer, close-to-metal expertise is almost considered esoteric. Despite that, the results can be impressive.
However, most GPUs and CPUs are one-size-fits-all solutions. GPUs can be used to train deep neural networks, mine Bitcoin, render animations, play video games, and many more. Decent in everything, best in nothing. Because of this, there's significant potential in designing specialized hardware for the sole purpose of running deep neural networks.
Think of each hardware as a car. An Intel CPU is like a Honda Civic: it properly performs everyday tasks, and you might even tune it if you want, but after all, it is built on top of a 1.6l naturally aspirated engine. On the other hand, a consumer-grade GPU is like a BMW 540i. Spooling up a 4.0l turbocharged V12 is not practical just to pick up the children from school, but if you want to launch an overtaking manoeuver while cruising the Autobahn at 160 km/h (or 100 mph if you like it), it's the perfect tool for the job.
Specialized hardware is like a Formula-1 car. They are useful for one job and one job only: running fast laps on racetracks. It's the same with hardware designed for using large neural networks.
Now that virtually all heavy computations are done in the cloud, you don't even have to deal with the cost of ownership of specialized hardware. For instance, the Mountain View, CA startup Groq (not to be confused with Grok, the language model of xAI) offers cloud solutions in addition to custom-built infrastructure.
The business of cutting costs
So, what are the viable business models? By looking at startups in the model optimization game, they either
develop an open-source toolkit and sell the access to the pro version,
sell consulting services,
sell specialized hardware,
sell access to specialized hardware via cloud services,
or any combination of the above.
Let's start once more with the software.
Model optimization toolkits and startups
As slicing the cost and size of large models is the easiest to do with software, the barrier of entry is the lowest in the model optimization space. So much so that even the most popular frameworks have built-in tools:
PyTorch has profiling tools, quantization, weight pruning, or a just-in-time compiler,
TensorFlow has quantization, weight pruning, and even a separate toolkit called LiteRT that enables running models directly on small devices,
and there are other smaller frameworks, such as the Intel Neural Compressor.
(And you can do knowledge distillation in any framework, as it's just model training in different clothes.)
One of the hurdles in applying these methods is finding a capable machine learning engineer to do the job. Thus, the idea of streamlining the model optimization to a single method call, just like Keras does for the training process, has potential merit.
Let's start with Pruna.ai, cleverly deriving their name either from prune for weight pruning or prana for lifeforce in Hindi. Their main product is the pruna compression framework, which includes a bunch of algorithms. With pruna, instead of having to set up the usual PyTorch/TensorFlow boilerplate, model compression can be done with a simple function call:
from pruna import smash
smashed_model = smash(
model=base_model,
smash_config=smash_config,
)
However, you still need to know how to configure the compression, which requires expertise from the user side. The paid version pruna_pro attempts to solve this by introducing an optimizer AI agent that should do the work for you. (At the moment, this is still an experimental feature.)
The pro version is available at $0.4/h, that is, you run the package and all the model optimizations locally on your resources, and you are billed after usage. For AWS, they have an Amazon Machine Image (AMI) offering, which is a pre-set instance image that you can spin up and subscribe to.
Pruna.ai seems to focus on B2B, aiming to capitalize on the rapidly lowering barrier of entry of large model ownership. Researching, developing, and training large models is no longer the privilege of giants like Meta, OpenAI, and X. Independent labs, like Anthropic, Midjourney, and Mistral AI, are popping up as the tech advances. In addition, even smaller machine learning teams at non-tech enterprises (like car manufacturers or retail chains) can build better and better custom models. Pruna.ai offers its services to them, as they explicitly state in their pitch deck, which recently brought in $6.5 million in seed funding.
Of course, there are other startups in the field, including but not limited to SqueezeBits (developing owlite), Mobius Labs (developing Aana), or Latent AI (developing their cloud platform called LEIP).
Low-level code optimization
As we've seen, reducing the size of a model is one way to cut costs and accelerate inference. Another one is going (near) to the hardware and making performance optimizations there. This is tougher than it sounds: model optimization techniques are relatively new, while low-level code optimization is as old as computing itself.
Let's see an example. Mako, founded in 2024, is one of the newcomers to the field, providing a (currently beta version) cloud platform for model deployment. Their model and hardware catalog are extremely limited for now, but I'm curious to see what's in the cards for them.
There's not much information: they optimize model performance by automatically generating high-performance code, they recently raised a seed round of $8.57 million, and Google's legendary Jeff Dean sits on their advisory board. (Though I'm not one to be easily impressed by big names, and neither should you.)
Their technology is best described by a snippet from their job board: "Mako is a venture-backed tech startup building software infrastructure for high performance AI inference and training on any hardware. There are three core components:
Mako Compiler automatically selects, tunes, and generates GPU kernels for any hardware platform (you'll be helping with this!)
Mako Runtime serves compiled models at high performance
Mako AI Agent generates GPU kernels using LLMs"
However, competing with the major cloud providers is a tough challenge. If the costs per hour would be a deciding factor, no one would use AWS. If ease of use would be a deciding factor, no one would use AWS either. When you go with one of the giants, you get
service level agreements,
an ecosystem of tools and developers,
data security,
and more.
Would saving a couple of bucks per hour be worth it if you lose access to a large pool of developers? Sure, as a solo builder, I love experimenting with new tech, but there are not enough of us out there that our ~$20-$30 per month spend is a good business.
On the other hand, "saving a couple of bucks per hour" is worth a lot more to the major cloud providers themselves! Think about it: if you already charge $10 per hour but can cut your costs in half, you win big! Zero sales effort needed. Thus, the probable conclusion of a startup such as Mako is selling to a major player.
There are other startups that have similar tech. One is Tiny Corp, developing Tinygrad, a framework 1) with tons of GitHub stars, 2) that I enjoy using, and 3) have no idea what the business model is. Currently, their only product is a customized machine learning rig, without any proprietary tech.
One more category to go. Let's talk about the toughest of all: building custom hardware.
Specialized hardware
If we rank the cost-cutting approaches according to their accessibility, the hardware business would finish at the bottom. For software, all you need is a semi-old notebook and a couple of computing credits. (And enough instant ramen to sustain homeostasis.)
Hardware is a different beast, though; besides the design, you need manufacturing and distribution. It's hard to juggle that many balls up in the air.
Nevertheless, there are successful ventures. Let's look at Groq, a Mountain View, CA-based startup that gained significant traction. Their flagship product is the Language Processing Unit, designed and optimized directly for neural network inference.

Currently, a Groq LPU costs about $20000, which is well below an nVidia H100, currently around $25000. However, unless you are actually building a cloud service, accessing the LPU-accelerated models through GroqCloud is probably a better deal for you.
As model optimization frameworks compete against PyTorch and TensorFlow, deep learning optimized cloud services compete against AWS and the other giants, and specialized hardware manufacturers compete against nVidia. Besides the high barrier of entry, the hardware business also takes more time to mature: the iteration cycles are far longer than in software.
Conclusion
Let’s revisit two of the figures we’ve seen earlier. First, the exponential explosion of the parameter counts.

This is reflected in the costs: when I’m writing this, the old gpt-3.5-turbo model costs $0.50/$1.50 per one million input/output tokens, the prices of gpt-4-turbo are $10.00/$30.00 per 1m i/o tokens. (Check out the OpenAI pricing page, as these might be outdated when you read this.)
On the other hand, technology tends to get cheaper. For instance, this is how the cost of human genome sequencing has evolved.
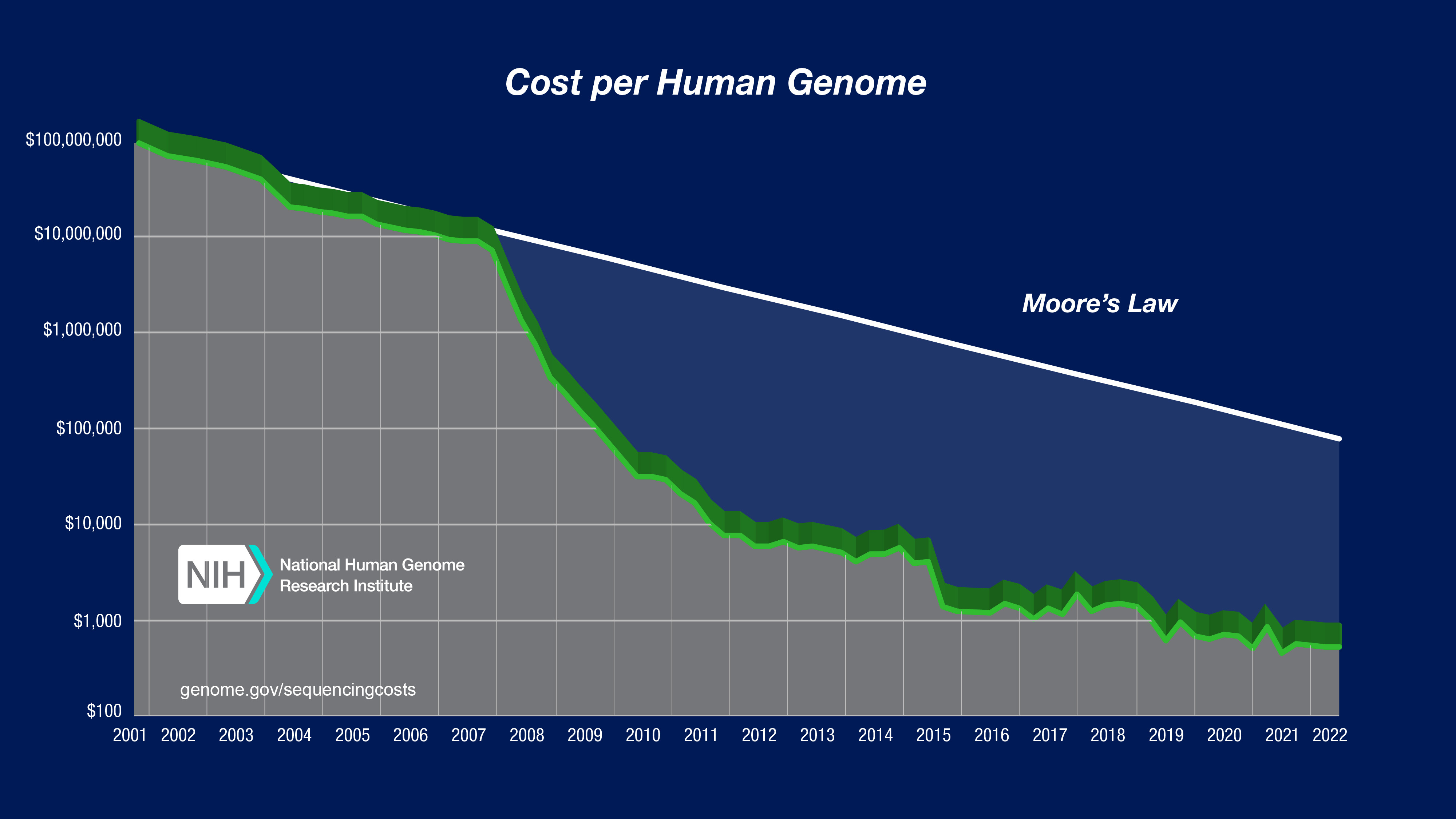
Check out the graph around 2007 and 2008, and gaze at the “exponential canyon.” Is this possible for AI? Are we heading towards that at all?
I don’t know. However, just considering that my father used to program computers (with punched cards) that filled rooms, and now the iPhone that I carry in my pocket can do better than, say, the entire NASA during the Apollo 13 mission, I’m confident (almost sure, so to say) that AI will get significantly cheaper.
The tools are there, and with most of the research and software being open, even you and I can get started right away. Maybe we’ll be the ones who bend the “cost of AI inference” graph like how it is with the “cost of human genome sequencing.”
Appendix
While researching this post, I have explored a couple of avenues that did not make it into the main story but are too interesting to ignore completely. So, I’m adding them to the appendix.
ChatGPT vs. Google: energy
When ChatGPT first came out, I quickly replaced Google searches with ChatGPT prompts. So, comparing a ChatGPT prompt to a Google search is a natural question to explore.
How much does a search/prompt cost for OpenAI/Google?
As reported by Google in 2009, a single search costs 0.3 wH of energy. What about an LLM prompt? Even though I could not find the exact dollar value, there are thoughtful estimates of the energy consumption. According to the analysis of GPT-4o prompts by Epoch AI,
a typical query (<100 words) costs 0.3 wH,
a long-input query (~7,500 words) costs around 2.5 - 4.0 wH,
while a maximum-input query (~75,000 words) costs a whopping 40 wH,
where the average US household consumption per minute is ~20 wH. Think of this the next time you spam the OpenAI/Anthropic API through Cursor, cramming your entire monorepo into a single request just to write a function that reverses strings.

(Note: the cited source measures input length in words instead of tokens, using an average of 0.75 word/token size.)
ChatGPT vs. Google: daily usage
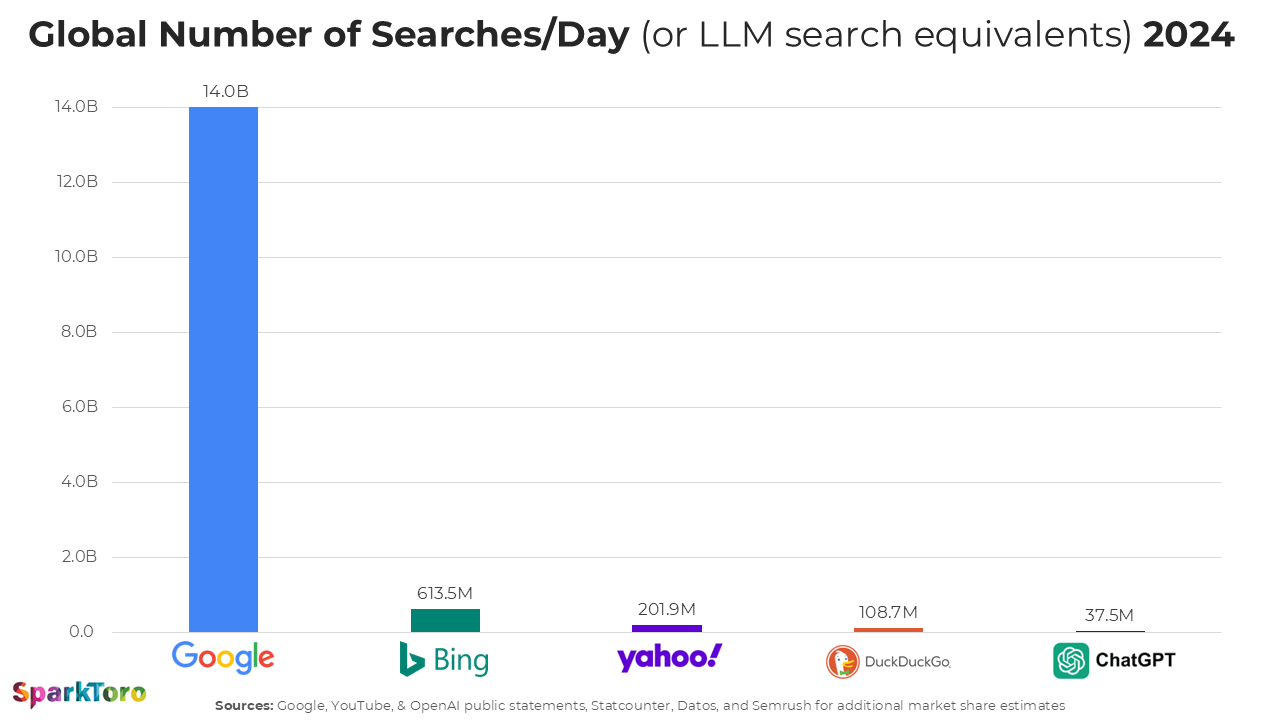
So, did LLM prompting truly replace Google?
Not really. Check out the global number of searches per day in 2024, according to SparkToro’s analysis. (The analysis calculates with a 30% ratio of search-like prompts, so the number below is (number of prompts) × 0.3.)
However, ChatGPT is growing at an insane rate. Check out how the monthly page visits turn out.

Here are ChatGPT's active user numbers for comparison.
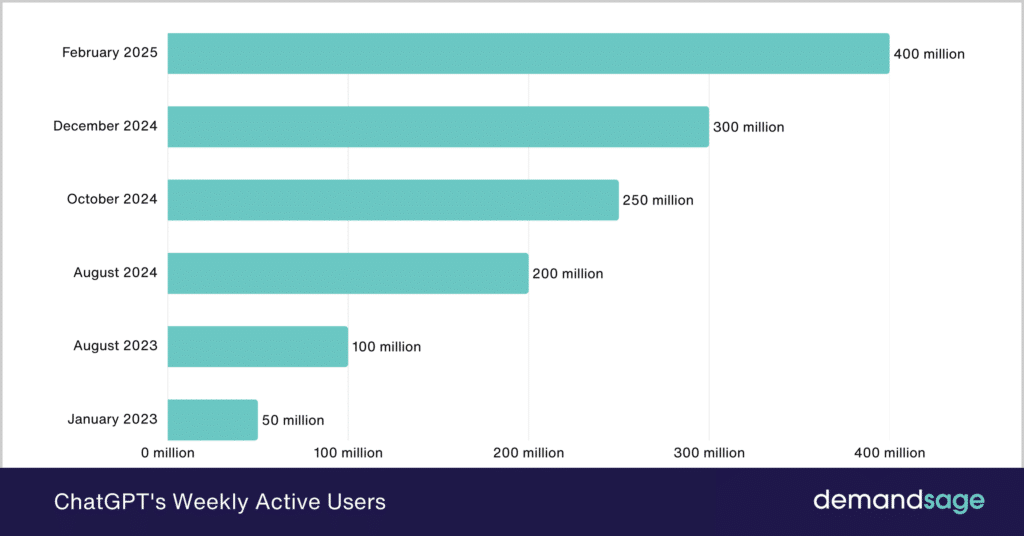
Although this growth is impressive, guess what! The number of Google searches still grew from 2023 to 2024 by 20% in some instances.

The report only considers spending through Ramp’s services. Here’s a direct quote from their methodologies: “Methodology: For this analysis, we looked at thousands of aggregated, anonymized transactions on Ramp cards and invoices paid through Ramp Bill Pay. For year-over-year comparisons, our sample size comprises customers who have been active with Ramp over that entire 12-month period.”
I like this text, but a neural network is not always the heart of an AI system. Other algorithms such as random forests, support vector machines or logistic regression are also used. These algorithms can actually help to reduce the costs of AI.